Omicron has been derived from a well-known 'burst-type' search pipeline called Q-pipeline (a.k.a Omega). Q-pipeline is able to detect and characterize detector glitches with a very good efficiency and precision. So, the idea was to adapt it for detector characterization purposes, i.e. to run it over many auxiliary channels. To achieve this, the original matlab code has been replaced by a C++ architecture and many steps have been removed to run faster. The name Omicron was chosen to recall the Omega inheritance.
Index:
- The Q-transform.
- The timing structure.
- Tiling.
- Conditionning.
- Whitening.
- Signal-to-noise ratio.
- Output data products.
- A concrete event example.
- How to run Omicron (Offline).
- Option file.
- GetOmicronTriggers: print Omicron triggers for a given channel
- GetOmicronPlots: print monitoring plots for Omicron triggers
The Omicron algorithm is based on the Q-transform which consists of projecting the data onto a template bank of windowed complex exponentials defined by a central time, a central frequency, and a quality factor. The window is approximately Gaussian. The template bank is constructed to cover a finite region in central time, central frequency, and Q such that mismatch between any sinusoidal Gaussian in this signal space and the nearest basis function does not exceed a specified maximum mismatch. This naturally leads to a template bank that consists of logarithmically spaced Q planes, logarithmically spaced frequency rows, and linearly spaced tiles in time.
For each tile, a signal-to-noise ratio (SNR) is computed as the ratio of the total energy content of the tile to the local power spectral density of the data. An Omicron trigger is then defined as a tile with a SNR value greater than a given threshold. See this section for a concrete example of how the algorithm works.
Two time scales are used when running the Omicron algorithm: the first one is used to apply the Q-transform analysis, the second one is used to estimate the local power noise spectrum (PSD).
Data are loaded and analyzed by chunk. Chunk after chunk, a data segment is sequentially analyzed. Chunks have a fix duration and two consecutive chunks overlap in time as defined by the user. The overlap is used to remove filtering artifacts and it must be large enough to remove these edge effects. The chunk structure can be represented by this cartoon:
|_______________chunk_________________|
| |_____________next chunk______________|
| |
|-------| overlap
|tttttttttttttttttttttttttttttt|
|tttttttttttttttttttttttttttttt|
For each chunk, triggers (t) are extracted, extracted the overlap divided by 2:
When processing a segment of data, the sequence of chunks does not generally match the segment duration. The last chunk of a segment is therefore adjusted to match the segment end. For the last chunk (6), only triggers not contained in the penultimate chunk (5) are extracted:
|-------------------- DATA SEGMENT ---------------------|
|__chunk1__| |
|__chunk2__| |
|__chunk3__| |
|__chunk4__| |
|__chunk5__| |
|__chunk6__|
Data segments shorter than a chunk cannot be processed. There is always a dead-time at both segment ends due to the overlap duration (overlap/2 at both ends).
A second time scale must be defined to estimate the PSD. It should be large enough to get a reliable noise average but small enough to account for slow noise variations. See Whitening for details.
The timing structure must be specified by the user in the option file. See Options file.
The parameter space is tiled in 3 dimensions: Q, frequency and time.
First, a set of Q-planes is defined according to the maximum mismatch value specified by the user. Each Q-plane is then divided in frequency rows logarithmically distributed. Finally, each frequency row is divided in tiles linearly distributed over time (over one chunk). The plots below shows the time-frequency tiling for 4 different Q values.
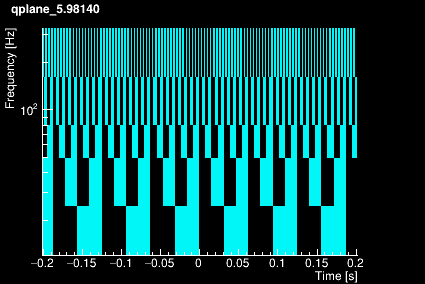 | 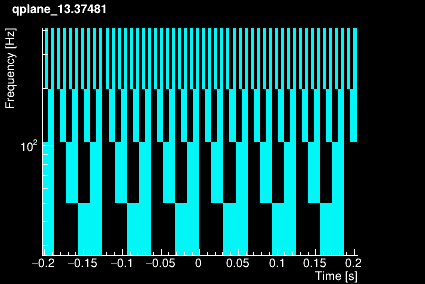 |
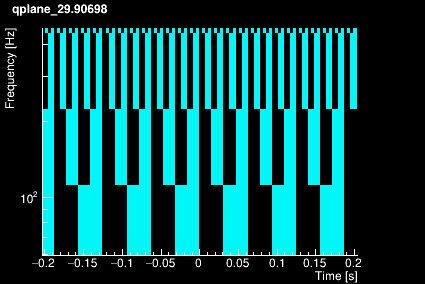 | 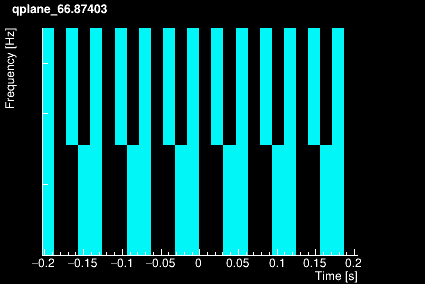 |
The tiling structure only depends on the Q range , the frequency range, the chunk duration and the working sampling frequency defined by the user. It is therefore built once for all when Omicron is initialized.
Once loaded, the input data chunk is conditionned. First, the input chunk data is downsampled to a working sampling frequency defined by the user. Only downsampling is supported. It is the user responsibility to make sure that the channel native frequency is high enough for this. Then, to avoid dynamic range problems, it is possible to high-pass filter the data (a user option must be specified). This is done with zero phase distortion by first forward-filtering and then reverse-filtering the input data stream using a 12th order butterworth high pass filter.
After conditioning, the chunk data is Fourier-Transformed and normalized by the local noise power density. The power spectrum density (PSD) is computed following the median-mean method described in gr-qc/0509116. The PSD is estimated with a 0.5 Hz frequency resolution provided the search is conducted above 1 Hz (more if below 1Hz). The PSD is then interpolated to fit the data working sampling rate specified by the user.
The number of PSDs used in the median-mean method is determined by the PSD length defined by the user. A PSD is said to be optimally computed when this length is fully used with input data. Since the data is sequenctially loaded, chunk after chunk, the PSD estimation may be sub-optimal for the first chunks of a data segments. The most recent data is always used to estimate the PSD (using an internal circular buffer). For more details about the PSD computation, see the Spectrum class.
With Omicron, the data is whitened twice. A first PSD is estimated using the conditioned data. This PSD is used to whiten the data. The result of this is used to compute a second PSD which is used to whiten the data again.
The PSD (or ASD) is one of the data products which can be saved on disk for sanity checks, see Output data products.
The conditioned and whitened data is projected onto the tiling structure. For each frequency band, characterized by a central frequency and a (approximatively) Gaussian window, the data is windowed and Fourier-transformed to go back in the time domain: X(t). For whitened data, the signal-to noise ratio is simply: SNR² = |X|² - 2. This expression is only valid if the data is perfectly whitened.
When running an Omicron analysis, several data products can be saved as an ouptut. This is defined in the option file as a set of keywords.
- Triggers, 'keyword=triggers'. An Omicron trigger is a tile with a signal-to-noise ratio above a given threshold. Triggers produced by Omicron are stored in a TTree structure (named 'triggers') saved in a ROOT file (other formats are supported). A trigger file is created for each channel and each chunk. The triggers produced by Omicron follow the GWOLLUM convention. For mor details, see the GWOLLUM convention.
- Maps, 'keyword=mapsnr, mapamplitude or mapphase'. An Omicron map is a time-frequency representation of the tiles. Maps are defined over one chunk. There is one map per Q value and one combined map. Maps are containers. They can contain eith the tile SNR, amplitude or phase.
- Conditioned time-series, 'keyword=timeseries'. For each chunk, the time-series can be saved (after conditioning).
- Whitened time-series, 'keyword=white'. For each chunk, the whitened time-series can be saved. Please note that requesting this data product requires additional computing (specific FFTs are performed).
- Whitened spectrum, 'keyword=whitepsd''. For each chunk, the power spectrum of whitened data can be saved. If the whitening was successful, it should be flat and equal to 2.
- PSD, 'keyword=psd'. For each chunk, the PSD can be saved.
- ASD, 'keyword=asd'. For each chunk, the ASD can be saved.
- Html report, 'keyword=html'. At the end of a processing, a html report can be dumped to present a summary of the analysis and links to all data products. If at least one web-supported graphical format (like png or gif) is present in the option file, plots will be displayed
This section summarizes the internal steps of Omicron. We used the example of a compact binary coalescence simulated signal injected in the data (a.k.a the big dog). After being loaded, the data vector is down-sampled to a user-defined working frequency. In our example, we downsampled the data from 16384Hz to 2048Hz.
The data vector is then high-passed at the lower range frequency value of the search (specified by the user). This is done with zero phase distortion by first forward filtering and then reverse filtering the input data stream using a 12th order butterworth high pass filter. In our example we used the search frequency range: 20Hz → 512 Hz.
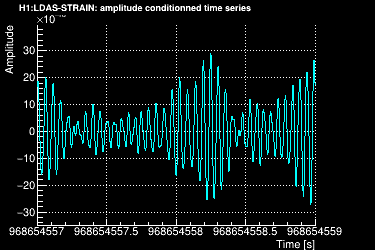
The power spectral density (PSD) is then computed using the median-mean method over the full time chunk. For our example, we used a chunk of 128 seconds. This means that 123 PSDs were averaged into one:
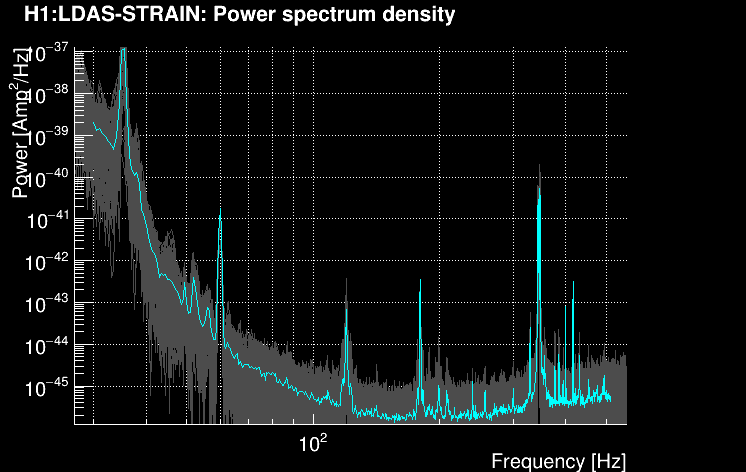
The data vector is Fourier-transformed and whitened using the PSD:
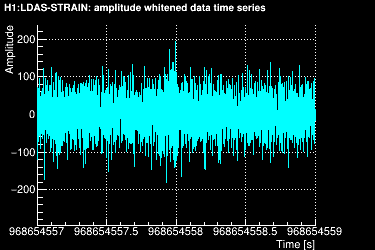
This data is projected over the Omicron tiles and the tile energy is computed. An amplitude SNR value is finally obtained for each tile. Here is what it looks like for our data segment (4 Q-planes were used):

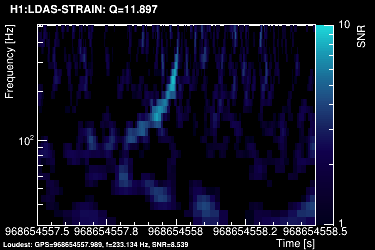
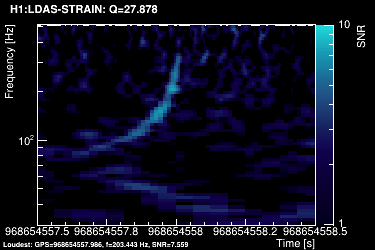
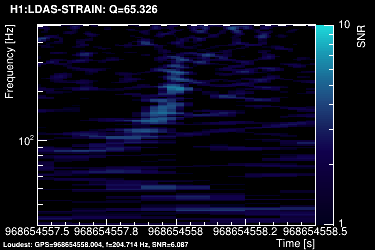
These 4 plots can be combined into one, plotting the highest SNR tile on the top:

When it comes to save triggers on disk, tiles with a SNR above a user-specified threshold are retained. The time and frequency information is given by the tile central point. An amplitude parameter is computed for each tile. It is given by SNR x sqrt(power) where power is a weighted average of the PSD over the tile.
Tiles are usually time-clustered to describe an event in totality. In this case, the cluster takes the time/frequency/SNR/amplitude value of the highest-SNR tile.
First you need to make sure your environment is well-defined by sourcing the Omicron setup script.
Then, to run Omicron, you need to provide a timing and a parameter file. There are different ways to run Omicron depending the number and the type of arguments:
- Over a single segment of data:
omicron 993574004 993574123 ./parameters.txt
This commands runs the Omicron algorithm continuously between 2 GPS times - Over a list of time segments:
omicron ./segments.txt ./parameters.txt
This command runs the Omicron algorithm over a list of disjoint time segments.segments.txtis a text file with 2 columns [GPS start] [GPS end] following the GWOLLUM convention for segments. - Over a single chunk:
omicron 993574004 ./parameters.txt
This commands runs the Omicron algorithm over one single chunk of data centered on a given GPS time.
For the 3 cases above, additional parameters can be given: if the "strict" keyword is given as the last argument, the omicron process will exit whenever an error is encountered. Without this keyword, omicron will simply skip the chunk for the faulty channel. Finally, an output timing can be given (a single segment or a segment file). In that case, only triggers in these segments will be saved to disk.
The user option file contains a list of parameters to pilot the Omicron processing. It is composed of a list of keywords to define a given parameter. Parameters are organized in different classes: DATA, INJECTION, PARAMETER and OUTPUT. Only 3 parameters are mandatory (the DATA class): a pointer to the frame file list, the list of channels to process and the sampling frequency. The option file will then look like this:
DATA FFL /virgoData/ffl/raw.ffl DATA CHANNELS V1:h_16384Hz V1:Pr_B1_ACp DATA SAMPLEFREQUENCY 2048With this configuration all the other options are set to default or 'guessed' from what is provided. In the following we list all the available options the user can include in the option file. None of them are mandatory. If an option is not provided, a default value is assigned or is guessed from the available information. Click here to get an example of option file
************** DATA CLASS
→ DATA FFL [path to ffl file]
Path to the 'frame file list' file to access the desired channels.
Two formats are supported:
- the 'ffl' format (Virgo convention, 5 columns):
[frame file path] [GPS start] [file duration] [0] [0]
- the 'lalcache' format (LIGO convention, 5 columns):
[observatory] [frame type] [GPS start] [file duration] [frame file path]
The input format is automatically detected by Omicron
This option is not mandatory but it should be used for a standard offline Omicron processing.
→ DATA CHANNELS [list of channels]
List of main channels to process. Channel names must be separated by spaces. This option
can be used over several lines when listing channels
*** This option is mandatory ***
→ DATA SAMPLEFREQUENCY [sampling frequency]
Sampling frequency to which channels will be downsampled.
Upsampling is impossible.
Only one value is possible, common to all channels.
This parameter is very important since it will strongly influence the processing time.
It has to chosen as small as possible.
************** INJECTION CLASS
→ INJECTION CHANNELS [list of injection channels]
Injection channels can be added to the main channels.
There must be exactly as many injection channels as main channels.
→ INJECTION FACTORS [list of factors for injection channels]
Injection channels are added with scaling factors provided with this option
There must be exactly as many factors as injection channels.
→ INJECTION FFL [path to ffl file]
If this option is not provided, the injection channels are loaded from the files listed
in the main FFL file (DATA/FFL option).
If an injection FFL file is provided, the injection channels are searched in a specific
set of files listed in this FFL file.
→ INJECTION FILENAME [injection file path]
Injections can also be performed through an injection file listing the source/waveform parameters.
The injection file must be a ROOT file generated with the InjGen class.
→ INJECTION SG [1/0]
Sine-Gaussian waveforms can be simulated and injected in the data when this option is set to 1.
One signal is injected in every chunk.
→ INJECTION SGTIME [negative range] [positive range]
By default, sine-Gaussian waveforms are always injected at the center of the chunk.
With this option, the time of the injection can be taken as a random value in a given time range.
The time range is defined with a negative and a positive range from the center (in seconds)
If only one value is provided, both the negative and positive range take this value.
→ INJECTION SGFREQUENCY [minimum frequency] [maximum frequency]
With this option, the frequency of the injection is taken as a random value in a given frequency range,
following a logarithmic distribution.
If only one value is provided, the injection frequency is fixed at that value.
→ INJECTION SGQ [minimum Q] [maximum Q]
With this option, the quality factor of the injection is taken as a random value in a given range,
following a logarithmic distribution.
If only one value is provided, the injection quality factor is fixed at that value.
→ INJECTION SGAMPLITUDE [minimum amplitude] [maximum amplitude]
With this option, the amplitude of the injection is taken as a random value in a given range,
following a logarithmic distribution.
If only one value is provided, the injection amplitude is fixed at that value.
************** PARAMETER CLASS
→ PARAMETER TIMING [chunk duration] [overlap duration]
Chunk and overlap durations in seconds.
→ PARAMETER FREQUENCYRANGE [minimum frequency] [maximum frequency]
Frequency range for the search.
If [maximum frequency] is too large, the Nyquist frequency will be used
→ PARAMETER QRANGE [minimum Q] [maximum Q]
Q range for the search. Q must be greater than sqrt(11).
→ PARAMETER MISMATCHMAX [maximum mismatch]
Maximum energy mismatch between tiles.
→ PARAMETER SNRTHRESHOLD [trigger SNR threshold] [map SNR threshold]
Tile SNR thresholds.
For triggers, a tile is saved if the SNR is larger than this value.
For maps, a map is saved if the loudest tile in the first time window is larger than this value
If only one value is provided, both thresholds are identical.
→ PARAMETER PSDLENGTH [data duration]
Optimal data duration, in seconds, used to estimate the PSD (median-mean).
→ PARAMETER HIGHPASS [high-pass frequency]
With this option the data are high-pass filtered before being processed.
The filter cutoff frequency must be given in Hz.
→ PARAMETER CLUSTERING [clustering method]
Cluster triggers before saving them on disk.
Only one clustering method is currently available: "TIME"
If this option is not given, triggers are not clustered.
IMPORTANT: this option is useless for triggers saved in a ROOT format:
clusters are never saved in GWOLLUM trigger files, only triggers are.
The clustering performed with GWOLLUM routines is always performed on the fly
when trigger files are loaded.
→ PARAMETER CLUSTERDT [δt parameter]
When the "TIME" clustering algorithm is selected,
it is possible to set the δt parameter with this option.
→ PARAMETER WINDOWS [list of time windows]
This option lists the time windows (in s) used for the plot output.
The windows are centered on the chunk.
→ PARAMETER MAPLOGSCALE [0/1]
The maps' vertical scale is a logarithmic scale if this option is set to 1.
→ PARAMETER MAPVRANGE [vertical range lower value] [vertical range upper value]
The maps' vertical scale range can be set with this option.
If only one value is given, it is used as the maximum.
If -1 is given, the scale is automatically adjusted to the maximum of the map.
→ PARAMETER FFTPLAN [FFT wisedom]
The FFT plan can be selected with this option.
FFTW_ESTIMATE, FFTW_MEASURE, FFTW_PATIENT, or FFTW_EXHAUSTIVE.
→ PARAMETER TRIGGERRATEMAX [maximum rate]
Maximum trigger rate [Hz] computed over one data chunk.
If the limit is exceeded, the triggers are not saved to disk.
→ PARAMETER TRIGGERBUFFERSIZE [buffer size]
It is possible to buffer the triggers produced by Omicron.
This way, triggers can be modified or deleted.
This option specifies the size of the buffer (number of triggers)
************** OUTPUT CLASS
→ OUTPUT DIRECTORY [path to output directory]
Path to output directory.
The directory must be created before running Omicron.
→ OUTPUT PRODUCTS [list of products]
List of output data products.
Possible products:
* triggers: trigger files
* map(snr, amplitude, phase): time-frequency maps
* timeseries: condition time series
* psd: noise power spectral density
* asd: noise amplitude spectral density
* white: condition and whitened time series
* whitepsd: noise power spectral density after whitening
* html: html web report
→ OUTPUT FORMAT [list output formats]
List of output formats.
Possible formats: root, txt, xml, png, gif, pdf, eps, ps, csv and many other...
→ OUTPUT STYLE [output style]
Name of an output style supported by the GwollumPlot class.
→ OUTPUT NOLOGO [1/0]
When a html report is requested, a background logo is used for the web page.
Setting this option to 1 will remove this logo.
→ OUTPUT VERBOSITY [verbosity level]
Verbosity level: 0, 1, 2 or 3
0: no printing
1: basic printing
2: parameters printing
3: full printing (debugging)
Omicron triggers can be printed with this tool. The command is very simple if triggers were centrally produced:
GetOmicronTriggers -c V1:h_4096Hz -s 934228815 -e 934232415
If you produced your own triggers, you need to specify the trigger files location:
GetOmicronTriggers -t "/path/to/my/triggers/*.root" -s 934228815 -e 934232415
This command prints every triggers between GPS times 934228815 and 934232415 for the channel 'V1:h_4096Hz'.
This tool is highly tunable. You can control the output, de-activate the clustering, select the triggers... For a complete list of available options, type:
GetOmicronTriggers -h
To get the list of available channels, type:
GetOmicronTriggers -l
IMPORTANT note: by default, triggers are time clustered. This can take some time. You can de-activate this option with the '-C 0.0' option.
To monitor the triggers produced by Omicron, use this tool to print a set of plots (for centrally-produced triggers):
GetOmicronPlots -c V1:h_4096Hz -s 934228815 -e 934232415
If you produced your own triggers, you need to specify the trigger files location:
GetOmicronPlots -t "/path/to/my/triggers/*.root" -s 934228815 -e 934232415
This command plots the trigger properties of channel 'V1:h_4096Hz' between GPS times 934228815 and 934232415.
This tool is tunable. For a complete list of available options, type:
GetOmicronPlots -h
|
|
Florent Robinet |