Conventions are used to define the GWOLLUM objects. These are a set of rules to make sure that GWOLLUM class functions work properly. This page describes the conventions used for the different GWOLLUM objects.
Index:
A segment is a time interval limited by 2 GPS times: [GPS_START] (included) and [GPS_END] (excluded). A segment list must respect the following rules:
- [GPS_START] is always larger than 700000000 (Mar 12 2002 20:26:27 UTC)
- For each segment [GPS_END] is greater than (and not equal to) [GPS_START]
- The list is time-sorted by increasing [GPS_START]
Segments can be individually tagged. This tag must respect conventions:
- [TAG] is an integer
- [TAG]>=0
- [TAG]=-1 is the default value (it basically means 'no tag')
Operations on segments (like merging, intersection...) requires rules for propagating the tags:
- [TAG1] * [TAG2] =
- -1, if [TAG1] = -1, whatever the [TAG2] value is
- -1, if [TAG2] = -1, whatever the [TAG1] value is
- Max([TAG1], [TAG2]), if [TAG1] > -1 and [TAG2] > -1
- [TAG1] + [TAG2] = Max([TAG1], [TAG2]).
A segment list can be described by several containers which have specific conventions:
→ Segments classThe segment list is internally managed by a Segments object. Overlapping segments are internally merged (in particular, if a segment ends where the next one starts). The merging of tags obeys to the [TAG1] + [TAG2] law described above.
→ Text fileA segment text file is an ASCII file listing the time segments (one segment per line). Several formats are supported defined by the number of columns:
- 2 columns: [GPS_START] [GPS_END]
- 3 columns: [SEGMENT_INDEX] [GPS_START] [GPS_END]
- 4 columns: [SEGMENT_INDEX] [GPS_START] [GPS_END] [DURATION]
- 5 columns: [SEGMENT_INDEX] [GPS_START] [GPS_END] [DURATION] [TAG]
A segment TTree is a ROOT TTree listing the time segments (one segment per tree entry). The [GPS_START] values are stored in a TBranch (double) named 'start' and [GPS_END] values are stored in a TBranch (double) named 'end'. The tree index is based on [GPS_START]. An optional TBranch can be added to store the tag values. It is named 'tag' and is of type int.
A stream (or data stream) is a time series sampled at given frequency. It is characterized by:
- A full name with the following format: [prefix]:[suffix]
- A prefix composed of 2 letters before the first column in the full name
To be continued...
A network is defined as a collection of N Streams. These N Streams can be combined in many different sub-networks. Networks are managed with the Network class.
Individual streams
Each stream must verify the conventions for Streams. In the network they are indexed with a stream index from 0 to N-1.
Network of streams
When working with N streams, 2^N sub-networks can form and must be indexed from 0 to 2^N-1. Sub-networks are organized in a 2-bit system where each stream is a bit set at 1 when it is part of the sub-network. The sub-network type gives the number of active detectors among the N detectors. The following table gives the example of a 4-stream network with its conventions:
| Sub-network index | Bits | Active stream indexes | Sub-network Type |
| 0 | 0000 | null | 0 |
| 1 | 0001 | 0 | 1 |
| 2 | 0010 | 1 | 1 |
| 3 | 0011 | 0,1 | 2 |
| 4 | 0100 | 2 | 1 |
| 5 | 0101 | 0,2 | 2 |
| 6 | 0110 | 1,2 | 2 |
| 7 | 0111 | 0,1,2 | 3 |
| 8 | 1000 | 3 | 1 |
| 9 | 1001 | 0,3 | 2 |
| 10 | 1010 | 1,3 | 2 |
| 11 | 1011 | 0,1,3 | 3 |
| 12 | 1100 | 2,3 | 2 |
| 13 | 1101 | 0,2,3 | 3 |
| 14 | 1110 | 1,2,3 | 3 |
| 15 | 1111 | 0,1,2,3 | 4 |
LIGO-Virgo Network
The LIGO Virgo network of detectors is defined as a 4 stream network. The stream index is also called the det index where:
det index = 0 → Virgo V1 det index = 1 → Hanford H1 det index = 2 → Hanford H2 det index = 3 → Livingston L1
Sub-networks can be defined using the network index defined in the previous table. For instance network index = 11 for V1H1L1.
Definition
A TimeSlides object is defined by a collection of N time offsets for a network of N streams. One set of these N time offsets is called a 'lag'. The following conditions must be verified:
- There should always be at least one lag. It is called the 'zero-lag' defined with N null time offsets.
- The lags should be indexed starting at 0 and incremented continuously.
- The zero-lag always has index=0.
Format
A TimeSlides object is a TTree where the entry number indexes the lag. The TTree should contain N branches 'offset_i' to store the time offset of stream with index 'i'.
CONTENT
A Triggers object must be composed of 2 TTree structures named 'triggers' and 'segments'. One optional TTree named 'metadata' can be added. The 2+1 TTree objects must be saved in the same ROOT TDirectory.
SEGMENTS
The 'segments' tree must contain 2 variables of type double and named:
start [s] end [s]
Each tree entry represents one continuous time segment in which the trigger generator was on and stable. Each time segment must follow the GWOLLUM convention for Segments. It is mandatory that the 'segments' tree is not empty and with a non-zero livetime. Time segments can overlap, if so, they are merged and considered as a single segment.
TRIGGERS
The 'triggers' tree must contain 10 variables of type double and named:
time [s] peak time (precision: 1e-6s) frequency [Hz] peak frequency tstart [s] starting time tend [s] ending time fstart [Hz] starting frequency fend [Hz] ending frequency snr [-] peak SNR q [-] quality factor amplitude [Hz^-½] amplitude phase [rad] phase
Each tree entry represents one trigger. The tree entries must verify the following conditions:
- Entries must be sorted by increasing 'tstart'.
- 'tstart' <= 'time' <= 'tend'.
- 'fstart' <= 'frequency' <= 'fend'.
- All 'time' and 'tstart' values must be contained in at least one time segment of the 'segments' object.
META-DATA
Meta-data can be saved along with the triggers. A TTree named 'metadata' contains one set of metadata per entry. Each tree branch represents a meta-data field. The name and type of meta-data are free. Only 2 meta-data fields are mandatory and expected to be found:
start [double] end [double]
These branches are used to associate a set of meta-data to triggers. The set of meta-data is applied to every trigger with start <= 'time' < end. For the sake of unicity, the segments [start-end] should not overlap (but can be contiguous). Moreover, they should not conflict with the segments structure. This means that the meta-data segments should be entirely contained in the trigger segments.
If the meta-data content is free, a set of pre-defined meta-data containers are reserved to be used by GWOLLUM applications. Filling these fields is not mandatory but very helpful for external applications:
'Mprocessname' [string] = process name used to produce the triggers 'Mstreamname' [string] = name of the processed stream 'Mdetindex' [int] = detector index 'Mfmin' [double] = minimum trigger 'frequency' value 'Mfmax' [double] = maximum trigger 'frequency' value 'Mqmin' [double] = minimum trigger 'q' value 'Mqmax' [double] = maximum trigger 'q' value 'Msnrmin' [double] = minimum trigger 'snr' value 'Msnrmax' [double] = maximum trigger 'snr' value
FILE NAMING
A trigger object must be saved in a ROOT format. Any name can be given to a trigger file as long it has a ".root" extension. There is a GWOLLUM convention which is optional but it is suggested to follow it:
[STREAMNAME]_[START]_[DURATION].root [STREAMNAME]: stream name as defined in the triggers metadata. [START]: starting time of the first segment of 'segments' rounded to the integer below. [DURATION]: [ending time of the last segment of 'segments' rounded to the integer above] - [START].
The Coinc class offers algorithms to set triggers in coincidence. Conventions are needed to use this class and to interpret resulting coincidences.
Indexing
- Stream index: In general, N trigger streams are used in a coincidence scheme. They are indexed from 0 to N-1.
- Pair index: All coincidence algorithms are based on pairing the streams. The Nx(N-1)/2 stream pairs must be indexed. This is done in a natural way. For example, with 4 streams, we have the following sequence:
Pair index Stream index combination 0 0,1 1 0,2 2 0,3 3 1,2 4 1,3 5 2,3 - Network index: Several combinations of trigger streams are possible. To index these combinations, we use the network conventions of indexing. However, in the context of coincidences, the network of type 0 and 1 are not considered (for N=4, network indexes 0, 2, 3, 8 are excluded).
Minimal coincidence
Whatever the coincidence scheme, the minimal requirement is a time coincidence characterized by a time window δt. 2 triggers are said in coincidence if the distance between them (using the triggers tstart and tend) is less than δt. If δt=0, then the coincidence is characterized by overlapping triggers.
Coincidence representation
The following diagram represents how the coincidence works. Two time lags (l and l') are represented. For each of them two cluster streams (i and j) are represented by a sequence of cluster start, end and peak times and by a segment. The green lines represent clusters found in coincidence. The red line represents the reference segment in which a coincidence is saved; if one of the cluster peak time or start time is outside of this segment, the cluster is not considered. For example, in the picture, the cluster i(k) for lag l is not consider for the coincidence.
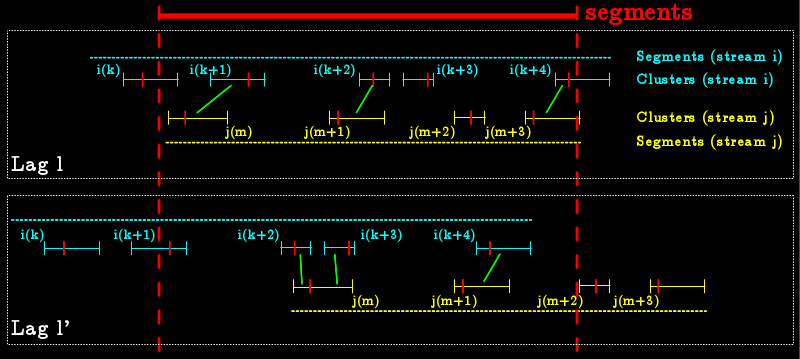
When using multiple lags, clusters are shifted but the reference segment is not.
Coinc object
The result of a coincidence can be saved on disk as a Coinc. The Coinc object is a collection of ROOT objects saved in a ROOT file:
- Single stream clusters are stored in a separate directory named 'stream_[ID]' where [ID] is the stream index. The clusters must verify the triggers conventions so they can be accessed with the ReadTriggers class.
- Time offsets are saved in a Timeslide TTree. This timeslide object must verify the time-slide conventions.
- A TTree named 'coinc' where each entry is a found coincidence. The tree branches are:
- 'type': type of coincidence (network type) - integer
- 'net': network index - integer
- 'lag index': lag index refering to the timeslide TTree - integer
- 'stream_[i]': trigger index referring to the triggers TTree in the sub-directory 'stream_[i]', i being the stream index - integer
Many GWOLLUM classes or applications come with the definition of a verbosity level usually set in the constructors. The printing is performed in the standard output stream. The verbosity level is an integer flag defined as follows:
- verbosity = 0 : minimal printing
- verbosity = 1 : basic printing to keep track of the evolution through the code
- verbosity = 2 : high level printing with more information about the process internal parameters
- verbosity > 2 : full printing with debugging information
|
|
Florent Robinet |